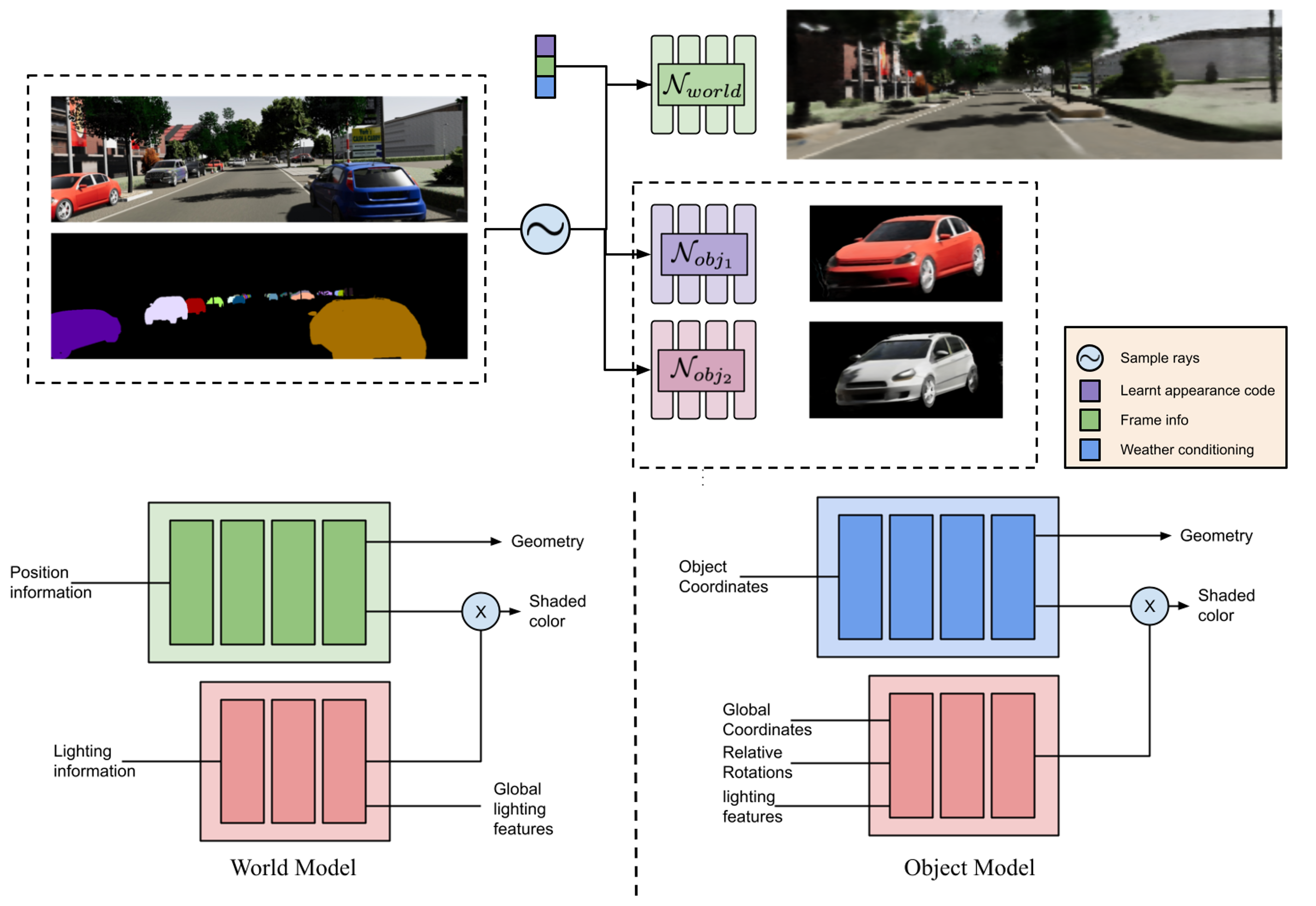
We present Lighting-Aware Neural Fields (LANe) for compositional scene synthesis. With the disentanglement of the learnt world model and a class specific object model, our approach is capable of arbitrarily composing objects into the scene. Our novel light field modulated representation allows the object model to be rendered in scenes in a lighting-aware manner.
The figure above shows the same world model learnt and reused as background scenes on each row, and object models composed into scene in arbitrary poses and locations under different lighting conditions. Note that the newly synthesized objects are shaded appropriately based on the scene lighting condition in which it is placed, which indicates our approach LANe can compose multiple object models and world model with physical realistic and consistent results.